与NFS,GFS,HDFS之类的文件系统类似,GlusterFS也是一种分布式文件系统,并且开源。使用者不用了解也不需知道底层文件的存储形式、分布,具有高扩展性、高可用性和弹性卷管理等特点。更多内容可移步官网了解,关于原理与机制计划单写一篇另述。

生产系统共有4台x86物理机,每台的硬盘配置如下
| 磁盘类型 | 规格(只列写大小与数量,其余规格略去) | 配置与用途 |
|---|---|---|
| SAS | 3x600GB | RAID1 + HOT BACKUP 安装操作系统 |
| SATA | 3x2TB | RAID5 用于文件系统的存储盘 |
由于SATA盘做了raid5,每台主机文件系统可用空间变为2/3,即4TB,结合高可用的需求,4台主机组成2x2的分布式副本,总共可用空间为8TB(实际还需要结合业务需求来考虑存储量和配置方式,因为这往往是决定磁盘个数与配置方式的主要因素)。
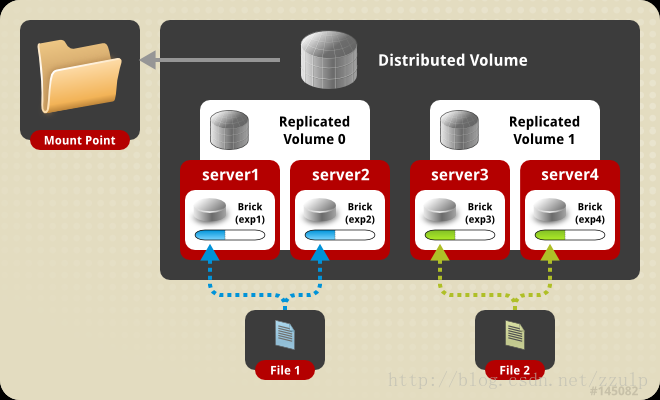
如上图所示,server1与server2组成一个复制组(副本),我们命名为复制组1,同样地,server3与server4组成了复制组2。同时,复制组1与复制组2又构成了分布式存储的关系,即复制组1与复制组2中的数据的合集才构成了完整的业务数据集。
由于生产中采用了红帽的RHEL7系列发行版,所以glusterfs我们也选择了使用红帽维护的版本(如果有厂商支持可以节省更多的时间去专注于业务开发,但如果想基于源码探索细节、业务系统对存储的要求不是那么严格、或者你刚刚试用,那么社区版本是你不错的选择)。
| 软件 | 版本 |
|---|---|
| 操作系统 | Red Hat Enterprise Linux Server release 7.1 Maipo |
| glusterfs | 3.7.9 (RPM) |
4台主机上需要安装glusterfs,软件的安装有多种选择,如果配置好了yum源且所需的rpm包已在源里,那么通过yum命令可以很方便的安装。也可以上传rpm的安装包(红帽提供的redhat-gluster-packages-3.7.9-12.tar.gz,解压后会有多个)至主机,使用rpm命令安装,但注意使用这种方式时很有可能出现依赖问题,所以无论哪种方式,一个可用的yum源可以为简化安装提供很多帮助。
上传软件包并解压
# tar -zxvf redhat-gluster-packages-3.7.9-12.tar.gz
解压后按如下顺序安装
# rpm -ivh glusterfs-libs-3.7.9-12.el7rhgs.x86_64.rpm
# rpm -ivh glusterfs-3.7.9-12.el7rhgs.x86_64.rpm
# rpm -ivh glusterfs-client-xlators-3.7.9-12.el7rhgs.x86_64.rpm
# rpm -ivh glusterfs-fuse-3.7.9-12.el7rhgs.x86_64.rpm
# rpm -ivh glusterfs-api-3.7.9-12.el7rhgs.x86_64.rpm
# rpm -ivh glusterfs-cli-3.7.9-12.el7rhgs.x86_64.rpm
# rpm -ivh userspace-rcu-0.7.9-2.el7rhgs.x86_64.rpm
# rpm -ivh glusterfs-server-3.7.9-12.el7rhgs.x86_64.rpm
注意,因为是使用RHEL操作系统,那么可能安装之前系统已经预先安装了glusterfs,版本可能与我们想要装的不一致,那么最好使用
rpm -qa | grep gluster先查看一下,如果已经预装了低版本那么使用 rpm -e 命令卸载相应的软件,再执行我们的安装即可。一般来说,生产环境的操作系统有固定的基线标准,所以该情况我们完全可以预先获悉以尽量避免在生产环境中安装了版本不一致的软件
如果某些rpm安装过程中报出了依赖问题,使用yum解决依赖即可。
# systemctl start glusterd.service //启动
# systemctl status glusterd.service //查看状态
# systemctl is-active glusterd.service //返回active表示启动,inactive 表示停止
# ps -ef|grep gluster //查看进程
# systemctl enable glusterd.service //开机启动
# systemctl list-unit-files|grep glusterd //查看开机启动,enabled为开机启动
假设我们已经按照系统规划中的内容完成了每台主机中3块SATA盘的RAID5配置(一般由运维人员进入bios手动配置),那么我们现在首先要做的就是在每台机器上做卷的划分
# mkdir -p /opt/glusterfs
# yum install -y system-storage-manager //安装ssm
# ssm create -n lv_opt_glusterfs --fstype xfs -p glusterfs_vg /dev/sdb /opt/glusterfs
这里首先创建了/opt/glusterfs这个目录,作为glusterfs的根目录,接着我们安装了system-storage-manager这个工具,注意这个不是必须的,安装它是为了让我们更轻松地划分卷与卷组并直接挂载(感谢运行部褚老师提供该思路),可以看到,接下来我们使用了一条命令就完成了上述所有事情。如果没有该工具,使用vgcreate、lvcreate等操作完成。
下面在fstab里写入挂载信息
echo /dev/mapper/glusterfs_vg-lv_opt_glusterfs /opt/glusterfs xfs defaults 0 0 >> /etc/fstab
cat /etc/fstab (验证一下是否写入)
修改isize
umount /opt/glusterfs/ //先卸载,为了改isize为512
mkfs.xfs -i size=512 /dev/glusterfs_vg/lv_opt_glusterfs -f
验证自动挂载
# mount -a
# df -h
创建glusterfs的数据目录
# mkdir -p /opt/glusterfs/data
重复以上步骤完成4台主机的软件安装与数据目录创建。
四台主机均完成以上操作后,我们就可以开始尝试配置集群了。
在glusterfs节点1(主机1上)上添加Glusterfs节点2、3、4到可信任存储池
登录到glusterfs节点1执行命令
# gluster peer probe 10.*.*.20 //此ip为Glusterfs节点2的ip,此处略去IP地址信息,下同
# gluster peer probe 10.*.*.21 //此ip为Glusterfs节点3的ip
# gluster peer probe 10.*.*.22 //此ip为Glusterfs节点4的ip
如果出现 probe:success 的提示即表示探测成功,并加入了可信任池
检查加入可信任存储池中的服务器状态
# gluster peer status
显示 Number of Peers的值应该为3,并且列出其余3个peer的信息,包括hostname [显示IP]、uuid[uuid具体值]、state Peer in Cluster (Connected)
正常显示以上内容时,代表所有节点已经正常被添加至集群内,下面可以开始创建glusterfs的分布式副本卷了
登录到glusterfs节点1上,执行命令如下(命令中隐去了IP的部分信息),注意只需在其中任一个节点上执行,这里选择节点1
# gluster volume create glusterdata replica 2 10.*.*.19:/opt/glusterfs/data 10.*.*.20:/opt/glusterfs/data 10.*.*.21:/opt/glusterfs/data 10.*.*.22:/opt/glusterfs/data
命令执行成功后应显示 volume create: glusterdata: success: please start the volume to access data
下面开始启动卷
# gluster volume start glusterdata //启动volume
集群启动后显示 volume start: glusterdata: success
查看卷状态
# gluster volume info glusterdata //查看volume状态信息
会显示volume的状态信息,其中Numbers of Bricks的信息为2 x 2 = 4,证明我们创建了分布式组的个数为2,同时每个组的副本数为2,与我们的设计相符
留坑待补
