Life is short, you need Python.

除了遥远读书时期的大大小小作业,这么正(dan)经(teng)的需求在现实生活中竟然还是第一次遇到:
面对如此正经的需求,人生苦短,你需要Python
对于发送微博有多种实现方法,可以使用廖神的SDK,需要下载(点击下载),功能比较简单也可以由我们自己实现,这里不采用SDK的方法,便于我们控制测试。
对比了网上的几类方法,发现貌似使用requests相比于比urllib2实现起来更简洁,这里没有对比二者性能问题,因为目前只是个人使用,并没有设计成服务。
pip3 install requests
pip3 install rsa
def wblogin():
username = USER_NAME
password = PASSWD
resp = session.get(
'http://login.sina.com.cn/sso/prelogin.php?'
'entry=weibo&callback=sinaSSOController.preloginCallBack&'
'su=%s&rsakt=mod&checkpin=1&client=%s' %
(base64.b64encode(username.encode('utf-8')), WBCLIENT)
)
pre_login_str = re.match(r'[^{]+({.+?})', resp.text).group(1)
pre_login = json.loads(pre_login_str)
data = {
'entry': 'weibo',
'gateway': 1,
'from': '',
'savestate': 7,
'userticket': 1,
'ssosimplelogin': 1,
'su': base64.b64encode(requests.utils.quote(username).encode('utf-8')),
'service': 'miniblog',
'servertime': pre_login['servertime'],
'nonce': pre_login['nonce'],
'vsnf': 1,
'vsnval': '',
'pwencode': 'rsa2',
'sp': encrypt_passwd(password, pre_login['pubkey'],
pre_login['servertime'], pre_login['nonce']),
'rsakv': pre_login['rsakv'],
'encoding': 'UTF-8',
'prelt': '53',
'url': 'http://weibo.com/ajaxlogin.php?framelogin=1&callback=parent.si'
'naSSOController.feedBackUrlCallBack',
'returntype': 'META'
}
login_url_list = 'http://login.sina.com.cn/sso/login.php?client=%s' % WBCLIENT
resp = session.post(login_url_list, data=data)
match_obj = re.search('replace\\(\'([^\']+)\'\\)', resp.text)
if match_obj is None:
logger.info('登录失败,请检查登录信息')
return (session, None)
login_url = match_obj.group(1)
resp = session.get(login_url)
login_str = login_str = re.search('\((\{.*\})\)', resp.text).group(1)
login_info = json.loads(login_str)
logger.info("login success:[%s]" % str(login_info))
uniqueid = login_info["userinfo"]["uniqueid"]
return (session, uniqueid)
代码中发送微博使用的接口为"https://www.weibo.com/aj/mblog/add?ajwvr=6&__rnd=%d" % int(time.time() * 1000,等号后面为时间戳,使用int(time.time() * 1000设置
class WeiboSender(object):
def __init__(self, session, uid):
super(WeiboSender, self).__init__()
self.session = session
self.uid = str(uid)
self.Referer = "http://www.weibo.com/u/%s/home?wvr=5" % self.uid
def send_weibo(self, weibo):
if not isinstance(weibo, WeiboMessage):
raise ValueError('weibo must WeiboMessage class type')
logger.debug('weibo must WeiboMessage class type')
if weibo.is_empty:
logger.info('没有获得信息,不发送')
return
pids = ''
if weibo.has_image:
pids = self.upload_images(weibo.images)
data = weibo.get_send_data(pids)
self.session.headers["Referer"] = self.Referer
try:
self.session.post("https://www.weibo.com/aj/mblog/add?ajwvr=6&__rnd=%d"
% int(time.time() * 1000),
data=data)
logger.info('微博[%s]发送成功' % str(weibo))
except Exception as e:
logger.debug(e)
logger.info('微博[%s]发送失败' % str(weibo))
这是一个典型的爬虫场景,大名鼎鼎诸如Scrapy、PySpider、Crawley、Portia等等各种框架均可轻松应对,但这对我们这种正经需求来说都太重了,我们使用 Beautiful Soup python库这个轻量级选手搭配requests可以很简洁地实现(经潇洒哥认证过的就是好 )。
from spider.eastmoney import EastmoneyParser
from spider.guba import GubaParser
from spider.ifeng import IfengParser
from spider.csrc import CsrcParser
spiders = [
EastmoneyParser(), #东方财富网
IfengParser(), #凤凰财经
GubaParser(), #股吧论坛
CsrcParser() #证监会新闻发布页面
]
currentIndex = 0
count = len(spiders)
def nextSpider():
global currentIndex
spider = spiders[currentIndex]
currentIndex = (currentIndex + 1) % count
print(currentIndex)
return spider
因为新闻可能来源于多个渠道,所以创建一个爬虫容器保存spider对象,每个爬虫对象实现自己的解析器就可以了,这样也方便后续添加其他新闻爬虫渠道,只需要实现要增加的爬虫对象并在容器中扩展就可以了。nextSpider方法简单实现了对于已有爬虫的轮询。
class Spider(object):
'''spider base class'''
def __init__(self, home_url):
super(Spider, self).__init__()
self.home_url = home_url
self.session = requests.session()
self.session.headers['User-Agent'] = USER_AGENT
def download_text(self):
'''get raw text such as html、json、or so on'''
resp = self.session.get(self.home_url)
resp.encoding = "utf-8"
return resp.text
def get_weibo_message(self):
pass
在创建Spider对象时,由于定义了解析的属性,所以只需要注入不同的解析对象,就能解析不同的网站内容了。目前只实现了东方财富网、凤凰财经、股吧论坛、证监会新闻发布页面的爬虫,如果后续扩展其它的媒体渠道,只要实现相应的Parser类,并在容器中添加即可。以东方财富网的wap版为例(wap版页面元素较少,比较容易定位),如下:
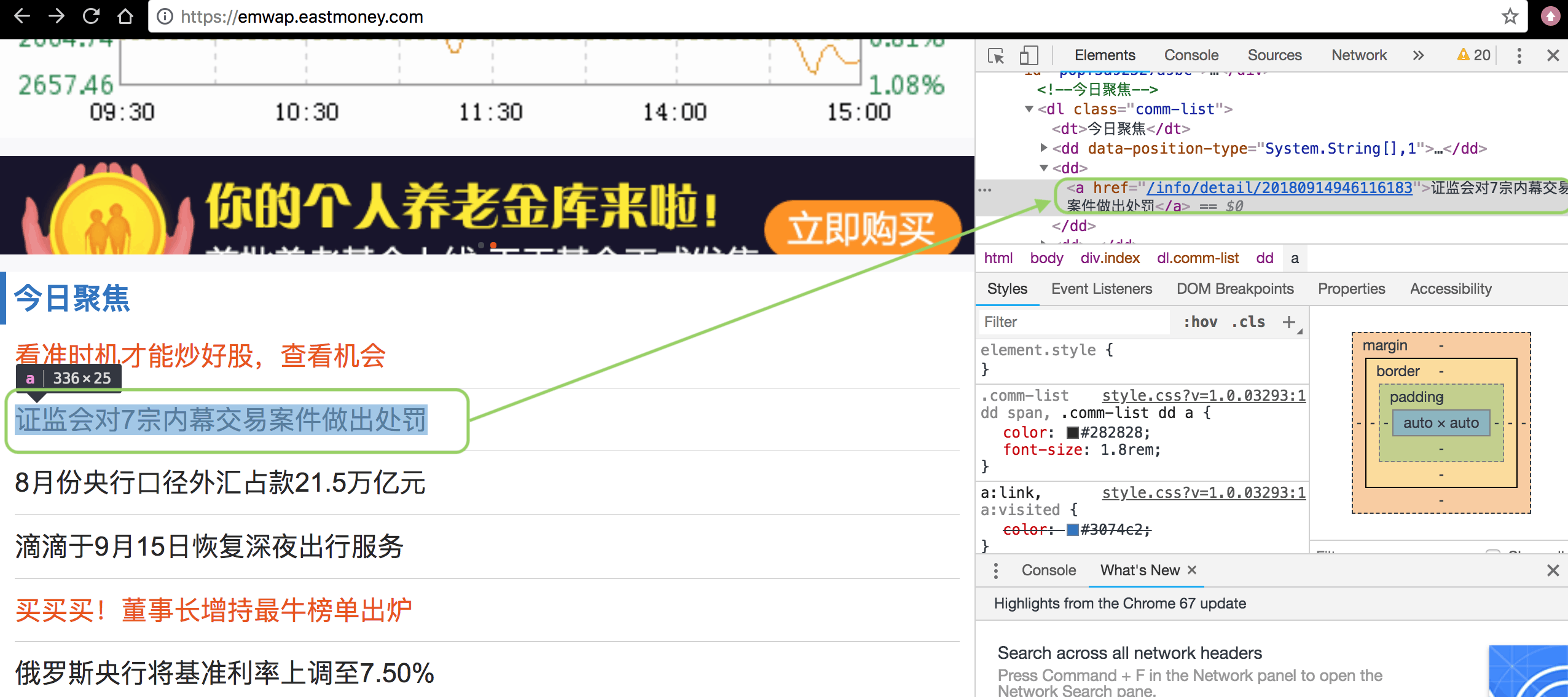
可以看到,我们需要的新闻类型(今日聚焦)在comm-list的class中,每个dd标签中包含一条新闻,我们只要定位到所有的a标签,并将a标签的text内容解析出来即为新闻的title,href解析出来即为新闻的链接,当然这里需要使用根url进行拼接一下,这两部分的组合即构成了我们微博的内容。
# -*- coding: utf-8 -*-
from __future__ import absolute_import
import bs4
import re
from spider.spider import Spider
from weibo.weibo_message import WeiboMessage
HOME_URL = "https://emwap.eastmoney.com"
class EastmoneyParser(Spider):
def __init__(self):
super(EastmoneyParser, self).__init__(HOME_URL)
def get_weibo_message(self):
html = self.download_text()
soup = bs4.BeautifulSoup(html, "html.parser")
div = soup.find(attrs={"class": "comm-list"})
items = div.find_all('dd')
msg = ''
weiboList = []
if len(items) > 0:
for item_num in range(1, len(items)):
item = items[item_num]
title = item.a.string.strip()
# 证监会 深交所 上交所 沪深 证券 央行 监管
if re.match(u'^\u8bc1\u76d1\u4f1a', title) or \
re.match(u'^\u6df1\u4ea4\u6240', title) or \
re.match(u'^\u4e0a\u4ea4\u6240', title) or \
re.match(u'^\u6caa\u6df1', title) or \
re.match(u'^\u8bc1\u5238', title) or \
re.match(u'^\u592e\u884c', title) or \
re.match(u'^\u76d1\u7ba1', title):
url = item.a.get('href')
url = HOME_URL + url
msg = "%s %s" % (title, url)
weiboList.append(WeiboMessage(msg))
return weiboList
使用re模块对新闻的标题做一个简单的匹配过滤,这里已定义好一些关键字,就直接写在了程序中,如果后续关键字比较多可以优化成字典
一次爬虫可以获取并构建0-n条微博内容,最后将所有的微博消息列表以list返回。在发送引擎类中使用方法sendWeibo调用spider对象中的get_weibo_message,获取爬到的微博消息list,逐条发送微博即可,间隔3秒以防止被屏蔽。
class SendTask(Thread):
def __init__(self, http, uid):
Thread.__init__(self)
self.stopped = Event()
self.sender = WeiboSender(http, uid)
def run(self):
logger.info("starting web comment task...\n")
self.sendWeibo()
while not self.stopped.wait(TIME_SLOG):
self.sendWeibo()
logger.info("end web comment task...\n")
def stop(self):
self.stopped.set()
def sendWeibo(self):
spider = spider_factory.nextSpider()
weiboList = []
weiboList = spider.get_weibo_message()
for weibo in weiboList:
self.sender.send_weibo(weibo)
logger.info("wait 3 second\n")
time.sleep(3)
发送微博的接口实现参考了网上的方法,修改后增加了上传图片的功能(不过貌似在我们正经的需求中也用不到),详细的代码后面将托管到github上。
这个流程,听起来,特别地像做自动化测试的同学,所以,web自动化测试框架Selenium,你值得拥有。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样,可以测试与各类浏览器的兼容性。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等
pip3 install selenium
准备你本地的driver,我用的是chrome,查看chrome对应的版本
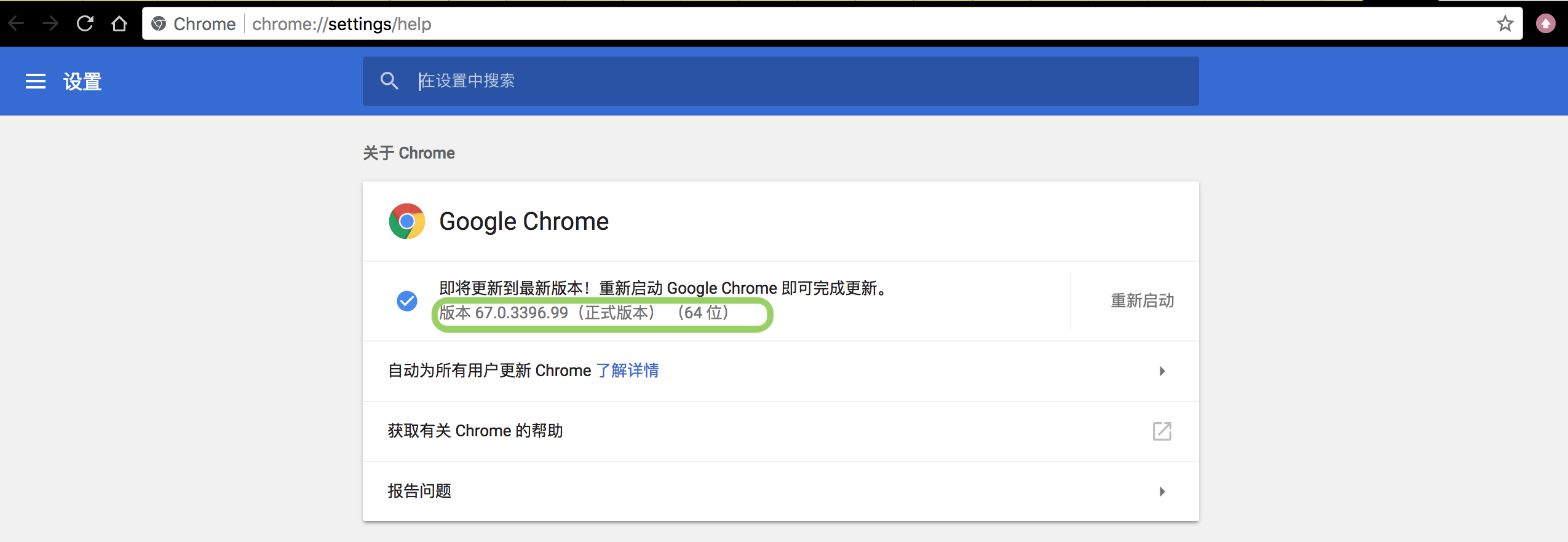
并选择对该版本支持的chromedriver
nodes文本文件中包含了版本支持说明

def driver_login(url, driver_location, username, passwd):
""" 使用webdriver登录:
url-登录地址
driver_location-本地driver路径
username-用户名
passwd-密码 """
driver = webdriver.Chrome(driver_location)
driver.maximize_window()
driver.implicitly_wait(7)
driver.get(url)
# driver.find_element_by_id("loginName").clear()
driver.find_element_by_id("loginName").send_keys(username)
driver.find_element_by_id("loginPassword").send_keys(passwd)
driver.find_element_by_id("loginAction").click()
time.sleep(5)
return driver
在登录时使用webdriver.Chrome()初始化一个driver,通过元素定位(通过id)找到登录框并发送用户名密码后提交,将driver返回。元素定位方法有多种,根据页面的具体情况可搭配使用,后面将会有其它示例。
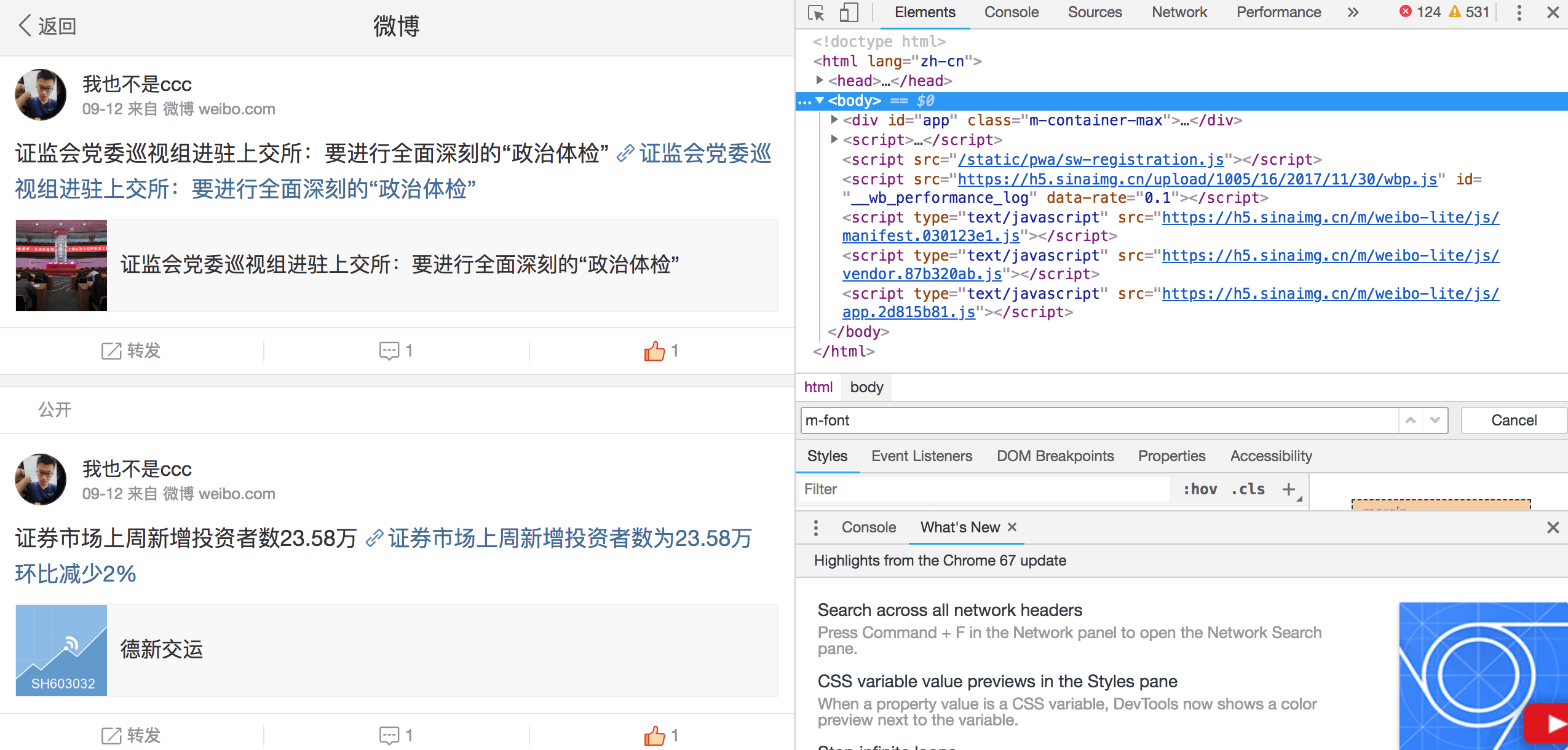
自动点赞与自动评论的过程在weibo_process_handler中实现
def weibo_process_handler():
""" 处理发送后的微博: 自动为已发微博点赞 自动发送评论 调用capture方法生成截图 """
driver = driver_login(url, DRIVER_LOCATION, USER_NAME, PASSWD)
driver.find_element_by_xpath('//*[@id="app"]/div[1]/div[1]/div[1]/div[1]').click()
# ActionChains(driver).move_to_element(top)
time.sleep(5)
count_like = 0
for count_weibo in range(1, 11):
#try:
# 等待页面加载出赞
WebDriverWait(driver, 10, 1).until(expected_conditions.presence_of_element_located(
(By.XPATH, '//*[@id="app"]/div[1]/div['+str(count_weibo + 1)+']/div/div/footer/div[3]/i'))
)
#找到赞的元素并发送点击
like_btn = driver.find_element_by_xpath('//*[@id="app"]/div[1]/div['+str(count_weibo + 1)+']/div/div/footer/div[3]/i')
like_btn.click()
time.sleep(1)
count_like += 1
#找到评论的元素并点击
comment_btn = driver.find_element_by_xpath('//*[@id="app"]/div[1]/div['+str(count_weibo + 1)+']/div/div/footer/div[2]/i')
comment_btn.click()
#定位到评论框并发送评论文字
if findElementByXpath(driver,'//*[@id="app"]/div[1]/div/main/div[1]/div/span/textarea[1]'):
comment_input = driver.find_element_by_xpath('//*[@id="app"]/div[1]/div/main/div[1]/div/span/textarea[1]')
comment_input.send_keys(choice(comment))
time.sleep(5)
if findElementByXpath(driver, '//*[@id="app"]/div[1]/div/header/div[3]/a'):
ActionChains(driver).click(driver.find_element_by_xpath('//*[@id="app"]/div[1]/div/header/div[3]/a')).perform()
elif findElementByXpath(driver,'//*[@id="app"]/div[1]/div/div[5]/div/div[1]/span'):
driver.find_element_by_xpath('//*[@id="app"]/div[1]/div/div[5]/div/div[1]/span').click()
comment_input = driver.find_element_by_xpath('//*[@id="app"]/div[1]/div/div[5]/div/div/div/div[1]/textarea[1]')
comment_input.send_keys(choice(comment))
time.sleep(5)
ActionChains(driver).click(driver.find_element_by_xpath('//*[@id="app"]/div[1]/div/div[5]/div/div/div/div[2]/button')).perform()
time.sleep(3)
#back_btn = driver.find_element_by_xpath('//*[@id="app"]/div[1]/div/div[1]/div[1]/i')
#back_btn.click()
driver.back()
else:
print('textarea is not found')
return False
print(count_like)
# 创建截图的存储路径,以时间方式命名
current_time_short = time.strftime("%Y-%m-%d", time.localtime(time.time()))
crnt_path = os.path.abspath('.')
pic_path = os.path.join(crnt_path, 'result', current_time_short)
isExists = os.path.exists(pic_path)
# 如果路径不存在,创建路径
if not isExists:
os.makedirs(pic_path)
# 创建截图的命名,以“年-月-日-时-分-秒”的时间格式命名,以png为后缀
current_time_long = time.strftime("%Y-%m-%d-%H_%M_%S", time.localtime(time.time()))
pic_path_test = pic_path + '/' + current_time_long + '.png'
#每隔1s定位微博个人页面元素,防止元素暂没有加载出来,超时时间为5s
WebDriverWait(driver, 5 , 1).until(expected_conditions.presence_of_element_located(
(By.XPATH, '//*[@id="app"]/div[1]/div['+str(count_weibo + 1)+']/div/div/footer/div[3]/i'))
)
#保存截图
driver.get_screenshot_as_file(pic_path_test)
#driver.refresh()
time.sleep(5)
#capture(driver, 1920, 906, pic_path)
driver.quit()
在处理点赞、评论、返回个人页面时,网络状态可能会影响到元素加载的速度,可以使用WebDriverWait()方法来等待元素的加载

| driver | 传入WebDriver实例,即我们上例中的driver |
|---|---|
| timeout | 超时时间,等待的最长时间(同时要考虑隐性等待时间) |
| poll_frequency | 调用until或until_not中的方法的间隔时间,默认是0.5秒 |
| ignored_exceptions | 忽略的异常,如果在调用until或until_not的过程中抛出这个元组中的异常,则不中断代码,继续等待,如果抛出的是这个元组外的异常,则中断代码,抛出异常。默认只有NoSuchElementException |
查找元素时有部分使用了find_element_by_xpath方法,即通过元素的xpath定位,该方法失败将直接抛出异常,我们将该方法封装一下,直接根据返回值在程序中实现逻辑控制。
def findElementByXpath(driver, element):
flag = True
try:
driver.find_element_by_xpath(element)
return flag
except:
flag = False
return flag
使用import smtplib可以很方便地以附件方式发送截图
btw,要注意使用网易邮箱发送时,需要使用客户端授权码代替密码,否则会出现535报错。
最后发送出的微博消息与截图大致如下左半部分所示,给自己的页面也点个赞😂